跟踪中国操作系统发展动态,向世界宣传中国操作系统,中国信创产业一定会成功!
图解Windows10+优麒麟双系统安装

为防止超速翻车,建议通读全文后再进行操作。
(此处双系统以 Windows 10+优麒麟 20.04 LTS Pro 为例,其他版本的系统仅供参考)

01
安装前的准备
四小步
第一步:查看电脑基础信息
按”win+r”快捷键回车确认,输入”msinfo32″,回车,出现系统信息界面,可查看 BIOS 模式:
BIOS 有多种模式,此教程以 UEFI 模式为例;
第二步:下载优麒麟镜像
官网下载:(www.ubuntukylin.com/downloads/)

页面下方还有多个开源镜像站下载途径可供选择;

注:下载完成后,为确认优麒麟系统镜像的完整性,可以使用 MD5 校验工具(网页搜索下载即可)验证 MD5 值与官网的是否一致。
第三步:准备一个 U 盘
打开冰箱门,拿出一个新鲜的U盘(或移动硬盘、DVD,此处以 U 盘为例)插在电脑上
要求:U 盘内存大于 4G;
第四步:制作启动盘
此处推荐 Ventoy,下载链接:https://www.lanzoui.com/b01bd54gb

选择结尾为 windows.zip 的最新版本进行下载解压,接着进入解压目录,双击运行 Ventoy2Disk.exe。

运行界面如下图所示:

① 是插入的 U 盘信息;
② 是此 Ventoy 的版本信息;
③ 是 U 盘内的 Ventoy 版本信息(没有安装 Ventoy 的显示为空);
④ 是安装选项,点击安装,就可以将 Ventoy 安装进对应的 U 盘里;
注:此处安装会提示是否格式化,也就是清空 U 盘内的所有数据,请提前将 U 盘原有数据备份。
安装完成后,设备内部 Ventoy 的版本信息就会显示出来,若内部版本低于安装包版本我们可以点击下方的“升级”选择进行升级。

注:升级操作是安全的,不会让 U 盘里已有的镜像文件丢失。
Ventoy 安装成功后,将优麒麟系统的镜像文件复制进到 U 盘,如下图:
此时 U 盘启动盘已经制作完成。以下为启动界面展示图:


02
安装进行时
三大步
第一步:关闭快速启动
如果不关掉可能会存在无法进入 BIOS 的情况
选择“控制面板–硬件和声音–电源选项–选择电源按钮的功能–更改当前不可用的设置”,在关机设置栏下找到“启动快速启动”,取消勾选,然后点击“保存修改”;
第二步:进行磁盘分区
磁盘分区是为了给优麒麟操作系统分配空间,默认选择分区尾部的磁盘(考虑到机械硬盘的读写特性,尽可能切靠前的分区)
首先需要在 Win10 上创建空白磁盘分区,选择“此电脑”–右键点击“管理”。

进入“计算机管理”页,点击“存储>磁盘管理”,选择要分割的磁盘空间,右键点击该磁盘,选择“压缩卷”。

此时会弹出压缩窗口,输入压缩空间量的大小,此处展示约分配 135G (空间分配建议最低不少于 30 G,如果大小不够可以重新分配一下磁盘空间,确保分区空余空间充足,原分区的大小也足够使用)。确认压缩空间量后点击“压缩”。
注:1G=1024MB,为方便计算,可以估算成 1G=1000MB。

压缩结束后,会多出一块可用空间,磁盘分区到此结束。

第三步:正式安装
插入制作好的 U 盘启动盘,重启电脑,在开机时按“F2”进入 BIOS 系统,然后在奇奇的带领下,一步步完成双系统的安装吧~
注:根据不同机型进入 BIOS 系统的快捷键有所不同,请根据自身机型搜索对应的快捷键进行操作。
首先关闭安全启动,通过左右方向键进入“Security”界面,按上下方向键移动到“Secure Boot”选项,回车进入修改状态,按上下键选择“Disabled”,回车确认。

接着通过左右方向键进入“Boot”界面,按上下方向键选择“Boot Option #1”选项卡,回车。选择启动方式为从 USB 启动,即选中自己的 U 盘,回车。

之后通过左右方向键进入“Save & Exit”界面,选择“Save Changes and Exit”,回车。在弹出的选择框里选择“Yes”,回车。

现在电脑开始重新启动,然后你会看到优麒麟开源操作系统安装的准备界面:

稍作等待,进入优麒麟新版安装界面,双击“安装 Kylin”。如下图:

接下来进入安装配置页面–选择语言、时区以及设置用户信息,大家根据自身情况进行设置哦。


直到出现选择安装方式界面,选择“自定义安装”。
注:记住我们是安装双系统,不要点击快速安装,否则有丢失数据的风险!

之后进到分区页面,如下图:

可以看到,系统已经存在 Windows 系统,“空闲”对应的就是我们刚刚压缩出来的空闲分区。 因为我们是安装双系统,所以接下来我们要做的就是将优麒麟系统安装在这个空闲分区内。
选中“空闲”分区–点击最右侧的“添加”按钮,进入新建分区页面。
首先添加根分区,奇奇在此处分配的大小是 80G,大家可以根据自身需求进行分配,但一定要确保之后有充足的空间可供使用,如下图:

由于 Windows 系统已经存在 EFI 引导分区了,所以我们再次不用添加 EFI 引导分区。
之后,添加 data 和 backup 分区,作为数据分区和备份还原分区,此处分别分配 20G。


全部分配完成后点击“下一步”,开始安装优麒麟开源操作系统。

等待安装完成,点击“现在重启”。
重启后便会出现选择系统界面,如下图:

通过上下键选择我们想要进入的系统,回车。到此,双系统已经安装好啦。
怎么样,你安装成功了吗?

03
常见问题解决方案
希望你用不到
Q:如果双系统安装完成后没有启动项选择界面,该怎么解决?
A:可能是启动项出现问题,可以下载安装用 EasyBCD 软件修复启动项。
Q:配置完分区后提示没有根分区、EFI分区、数据备份或还原分区,该怎么办?
A:根分区对应的是“/”,EFI 分区需要在分区时将“用于”类型改为 EFI,数据备份分区对应的是“/data”,还原分区对应的是“/backup”,请根据提示查找对应的分区是否创建。
Q:配置完分区提示“只能存在一个 EFI 分区”,该怎么办?
A:应该是已有的 Windows 系统也存在 EFI 分区,我们需要把自己添加的 EFI 分区进行删除。
Q:笔记本安装完双系统之后,进入 Windows 系统出现花屏,该怎么办?
A:笔记本只有集显,在系统启动时会先加载优麒麟的显卡驱动以用来加载选择系统的界面,致使在选择进入Windows时出现花屏情况
解决办法:首先,进入优麒麟系统中,打开 /etc/default/grub:
将如下语句取消注释即可(删掉 #)。
# Uncomment to disable graphical terminal (grub-pc only)
# GRUB_TERMINAL=console
Q:使用 USB 启动盘安装时,出现”try ubuntu kylin without installation”或“install ubuntu kylin”,Enter 选择“安装”后,显示器黑屏无任何显示,该怎么办?
A:
方法一:显示黑屏,可能是显卡显示的支持有问题,尝试手动修复。
移动光标到”install ubuntu kylin” , 按”e”进入编辑模式,进入命令行模式,


找到”quite splash”然后去掉”—“后,添加“nomodeset”,按 F10 安装。


注:依照不同显卡进行不同显卡驱动选项的添加,此处使用的是Nvidia显卡,添加 nomodeset。
方法二:移动光标到“Try Ubuntu Kylin without installing(safe graphics)”进入安全试用界面尝试使用。
Q:系统安装完成之后,提示未检测到无线网卡,该怎么办?
A:重启,然后在 grub 界面选择高级选项,选择低版本内核,回车,查看网络是否正常:



04
结语
投个票吧投个票吧
如果有什么看不懂的地方,或者在安装过程中出现了文章中未提及的问题,欢迎小伙伴们加入交流群一起探讨,群里不仅有 Linux 忠实爱好者,还有不定时的惊喜福利等你哦~!
扫一扫添加小优微信拉你进群:


构筑智能体时代 | 中兴通讯发布新支点AIOS


当AI应用从”你问我答”迈向”你说我做”,智能化的竞争焦点正发生深刻转变:企业需要的不再仅仅是单点AI能力,而是能够理解意图、调用工具、协同业务、持续进化的智能体操作系统。
2026世界人工智能大会(WAIC)期间,中兴通讯正式发布面向AI时代打造的创新技术底座——新支点AIOS。这一系统正从试点验证迈向规模化应用新阶段,全面展现了在行业场景、家端产品、终端产品三大方向的技术突破与应用成果,加速从技术底座向”端—边—云”协同的智能生态体系演进。

新支点AIOS不仅让设备拥有AI能力,更致力于为行业、家端、终端应用场景构建一个统一、安全、轻量、高效的智能体运行底座,推动AI从单点工具走向系统化、场景化落地。

新支点AIOS以智能体操作系统的形态,正在成为产业智能化升级的核心底座。目前,系统已形成面向工业、矿山、冶金、城轨、电力、政务等行业以及智慧园区场景的解决方案,并与多家行业龙头企业建立深度合作,推动传统产业智能化变革。
在智慧园区场景中,AIOS支撑起7×24小时数字安防值班员与能耗管理助手,实现园区安全巡检、异常预警、能耗分析与运营管理的智能化协同,显著提升园区运营效率与安全水平。
在冶金行业,AIOS构建生产智能中枢,围绕能耗优化、故障预警、生产协同等关键环节,助力企业实现生产效率提升与运营成本降低的双重目标。
在矿山场景中,AIOS部署安全预警、生产调度、经营管理等多类AI数字员工,辅助矿山企业提升作业安全性、调度效率和经营管理精细化水平。
在城轨领域,AIOS打造企业级通用智能体平台,率先在办公场景落地应用,并逐步向生产调度、运维管理等核心业务场景延伸,构建全场景智能支撑能力。
在电力行业,AIOS赋能”数字员工”系统,推动人机协同作业模式,大幅提升一线业务处理效率与准确性。
在政务场景中,AIOS助力城市基础设施运维管理,实现问题发现、任务派发、处置跟踪和应急响应的全流程智能化升级,提升城市治理现代化水平。
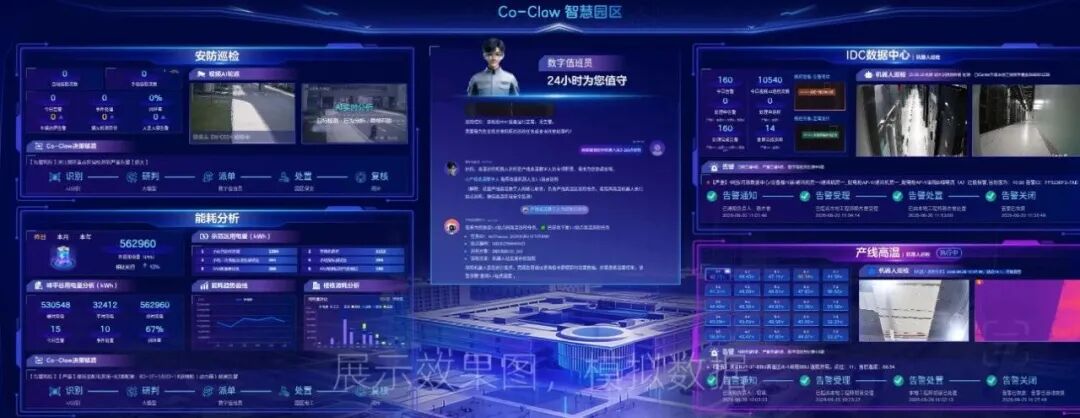
通过上述行业实践,AIOS正将AI能力从单点工具带入真实业务流程,成为支撑行业智能化升级的关键底座。
与此同时,AIOS也带动中兴通讯智算一体机等硬件产品同步落地,形成”软件平台+ 硬件底座 + 行业方案“的软硬一体化竞争力,为客户提供更完整、更可部署、更可持续演进的智能化解决方案。

在家端产品领域,新支点AIOS已在AI中屏和AI路由器两大核心场景完成试点验证,展现出家庭AI入口的巨大应用潜力。
在AI中屏中,AIOS已支持”私人助理“、”家庭教师“等典型场景。用户无需在多个应用间频繁切换,仅通过自然语言即可完成信息查询、家庭管理和生活服务,实现真正意义上的便捷交互。
在AI路由器场景中,AIOS化身”家庭网络管家“,支持WiFi管理、网络配置、上网控制等近20个家庭生活场景,让传统网络设备升级为家庭智能管理中枢。用户可通过自然语言完成网络设置、上网时段管理、设备控制等操作,大幅降低家庭网络使用门槛。
为适配家端设备对资源、成本和响应速度的高要求,新支点AIOS采用”本地热词匹配+ 向量检索增强 + 大模型生成兜底“三级机制,在响应速度与语义理解之间取得有效平衡。

同时,系统通过深度裁剪与瘦身,实现了极致的轻量化设计;同时通过系统提示词优化和任务调度策略改进,显著降低了Token消耗,任务级Token消耗较上一代降低一半。这一突破使AIOS能够更好适配AI中屏、路由器等资源受限设备,推动家庭AI从概念演示走向真实部署。
在家庭安全方面,AIOS构建了覆盖输入输出围栏、技能扫描、沙箱隔离等能力的全栈安全体系。系统还支持Node主动事件推送,可实现烟雾报警、燃气泄漏等异常情况实时上报,让家庭设备具备更强的主动感知与智能响应能力。

在云电脑等终端产品领域,通过统一架构集成与系统级优化,新支点AIOS在性能、功耗和体验上实现全面提升:内存占用显著降低,简单任务平均响应时间大幅缩短,Token消耗明显下降,真正实现”即点即用、极速响应”。
更重要的是,AIOS支持端侧模型运行,使更多智能任务可在本地完成。这不仅降低了延迟、提升了响应速度,更进一步保障了用户隐私安全,为端侧智能体的大规模应用奠定基础。
面向复杂任务处理,AIOS构建了智能体任务处理引擎。基于自研Harness Agent Loop技术,系统能够实现智能体分级调度、任务拆解与并发执行,让终端不再只是被动等待用户操作,而是能够根据用户意图主动理解、规划和执行,实现从”工具辅助”到”自主协同”的跃迁。

新支点AIOS的价值,远不止于提升某一类设备或某一个行业场景的AI能力。通过统一架构、开放协议、安全机制和极致优化,它正在构建一个可复用、可扩展、可持续演进的智能体操作系统。
在行业侧,它让AI数字员工进入园区、矿山、冶金、城轨、电力、政务等真实业务现场;在家庭侧,它让AI中屏、路由器等设备成为自然交互入口;在终端侧,它让云电脑等产品具备更强的意图理解和任务执行能力;同时在企业内部,它也持续反哺研发、运营和管理提效,形成内外联动的智能化闭环。
从“行业智能“”家庭智能“到”端侧智能“,新支点AIOS正在贯通更广泛的应用场景,推动AI从单点能力走向系统能力,从工具辅助走向自主协同。
面向未来,中兴通讯将继续深化新支点AIOS在复杂任务处理、多智能体协同、端云一体化、安全可信等方向的技术创新,携手产业伙伴共同构建万物互联、智能协同的AI新生态。
智能体时代已经到来。新支点AIOS,正在成为驱动这一时代加速落地的新引擎。
新支点技术

扫码关注
服务热线丨400-033-0108
技术邮箱丨os@gd-linux.com



