2026 年 4 月 15 日,统信软件正式发布统信桌面操作系统 V25。历经技术积淀与生态深耕,产品以“智慧生产力、高效生产力、可靠生产力”三大支柱,重新定义国产操作系统的成熟与智能,为千行百业带来从“可用”到“智用”的跨越式体验。

01 廿载磨砺

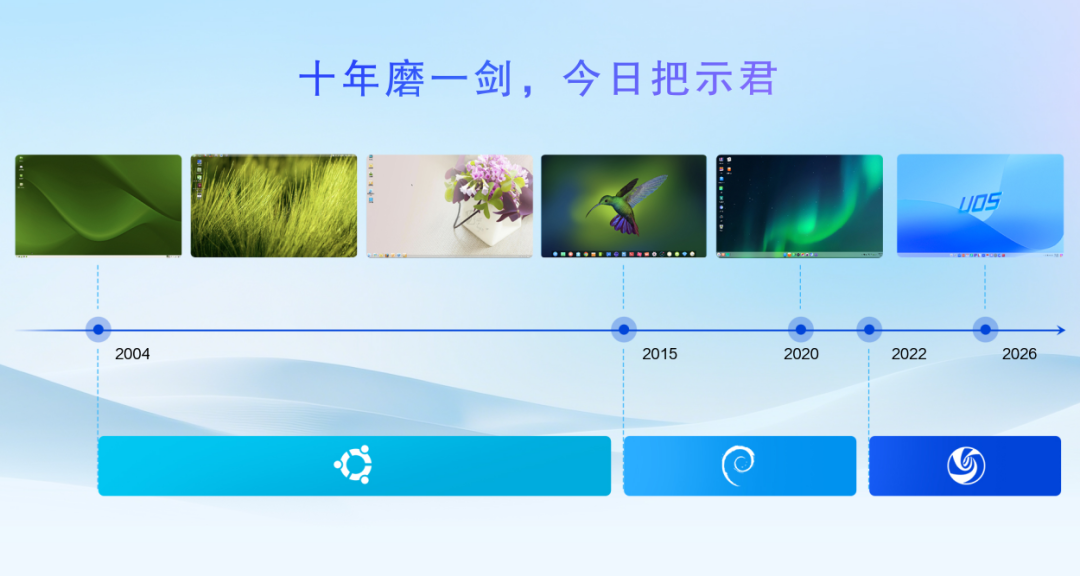
统信软件高级副总裁、CTO 张磊回顾了统信 UOS 二十余年的发展历程:
-
从最初面向中国用户的汉化产品起步,到组建专业团队打造深度操作系统,并发布国内首个操作系统应用商店;
-
自研深度桌面环境(DDE),实现绚丽的渲染效果与良好扩展性;
-
统信软件成立后,推出统信 UOS V20 获得市场成功;
-
逐步以共建、共享、共治的开源模式,独立发展桌面操作系统根社区 deepin,实现独立上游演进。
“商业版本+根社区”的双轮驱动模式,使统信 UOS 可自主掌控源代码,从根源上规避上游“断供”风险。
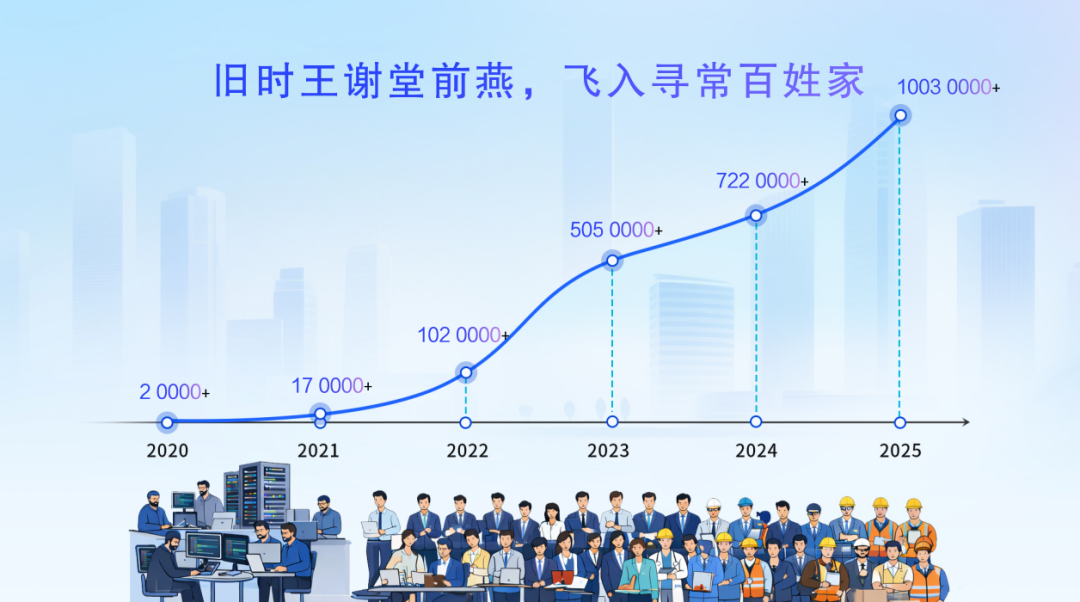
张磊表示:“十年磨一剑,今日把示君。”统信 UOS 的发展历程印证了这一点:其核心用户群从最初的技术高手、极客群体,扩展至如今的千行百业;生态适配数量更是由 2020 年的 2 万余款增至 2025 年的超千万款,增幅高达 500 倍。这恰是“旧时王谢堂前燕,飞入寻常百姓家”的技术普惠写照。
面向 AI 浪潮,张磊指出:2025 年起 AI 从聊天机器人迈入智能体(Agent)阶段,具备了“动手干活”的能力。但 AI 基于概率模型存在不确定性,安全必须前置。《易经》云:“君子以思患而豫防之。”统信 UOS 在 V25 上构建了三大安全体系:
-
内核安全:访问控制等内核级创新;
-
磐石系统:不可变技术保护系统免受误操作与恶意攻击;
-
应用安全:如意玲珑技术将每个应用或智能体封装于容器中,超出边界即阻断。
三大安全体系共同支撑起广泛的智能体生态,为用户提供安全、可控的智能化体验。
02 三大生产力
统信软件副总裁王耀华系统介绍了统信桌面操作系统 V25 在智慧、高效、可靠三大生产力维度的技术突破。

◉ 智慧生产力:操作系统即智能体
UOS AI 3.0 正式进入 Agent OS 时代,系统升级了 AI 架构,新增 AI SDK V2 版本,增加了智能体服务层。
在智能平台方面,全面支持 MCP 和 Skills 外挂式能力扩展,具备任务拆解与多智能体协作能力,同时还与合作伙伴共同研发了二进制智能托底技术,让传统应用也能被智能体调用。
在智能办公方面,写作智能体支持本地素材和联网搜索自动成文、文档引用链接方便快速溯源,可接入企业私有化大模型;数据分析智能体可自动分析图表、生成本地脚本、输出深度报告与图表。
在智能协同方面,UOS AI 天然具备 7×24 小时 Claw 模式,与飞书、钉钉、QQ、微信一键打通。

◉ 高效生产力:交互、文档、跨端三重革命
统信桌面操作系统 V25 引入全新“行云设计”语言,核心理念是高效、沉浸、流畅。音频架构升级到 PipeWire,实时性提升 80% 以上。基于两年多用户访谈,对 20 多个模块的 150 多个功能进行了深度优化。
文档管理方面,搜索支持图片检索和自然语言搜索,秒级响应;提供分组模式和标签页设计;文件分享支持 Samba 自动降级、NFS 服务端拷贝,文件投送一键互传,外置 U 盘拷贝性能最高提升 50%。跨端协同提供了移动客户端,实现电脑与手机之间的数据流转。
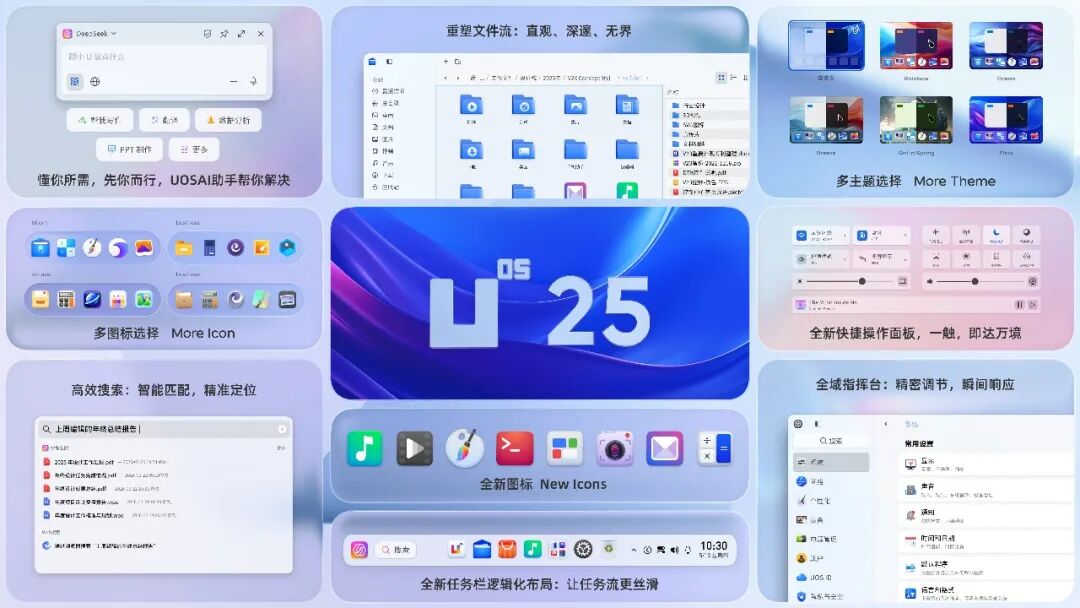
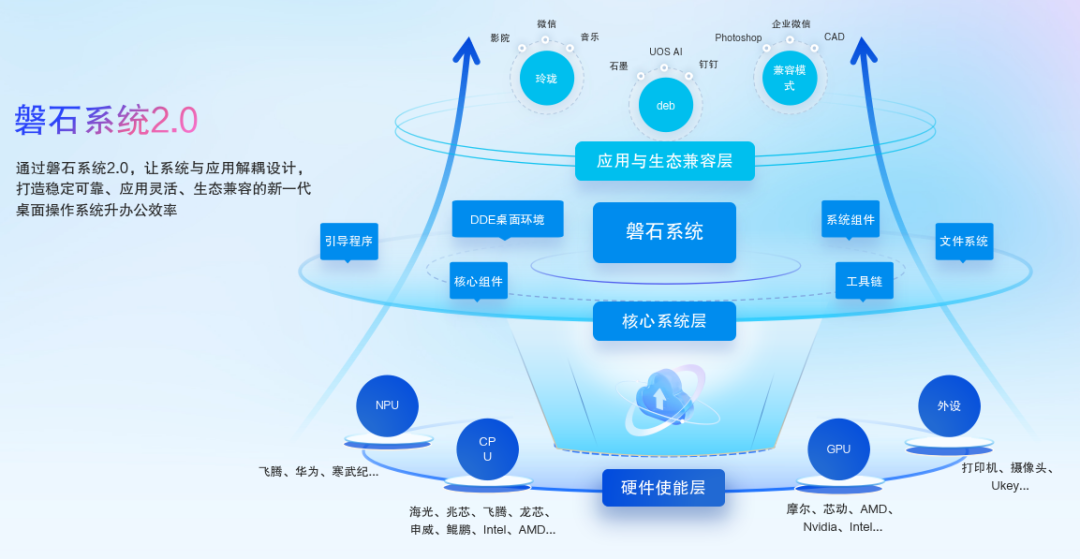
◉ 可靠生产力:稳定、安全、生态三重基石
磐石系统 2.0 实现系统核心不可变保护及系统与应用分离。差分更新技术降低带宽占用约 50%;快照技术让备份还原更快捷,支持电子教室等场景的每次开机自动还原。
基于 6.6 内核,统信桌面操作系统 V25 在安装部署、开机、大文件拷贝等场景的性能均优于上一代。USEC 2.0 实现了统一安全架构(性能开销比传统 SELinux 下降超 80%)、D-Bus 安全加固、企业级磁盘加密系统(部分国密算法性能提升 3 至 10 倍)以及软硬件协同防护。
生态方面,硬件兼容最新政府采购 CPU 型号,软件应用商店上架超 1 万款,玲珑格式超 6000 款,Windows 兼容引擎提供超 4000 款应用,并配套企业级桌面管理解决方案。
03 北京软交所
北京软件和信息服务交易所有限公司副总经理黄平分享了软交所与统信软件在国企信创落地中的探索与实践。

北京软件和信息服务交易所有限公司(简称软交所),由工信部和北京市政府联合发起成立,专门做软件服务和信创推广,拥有 CNAS 实验室认证,牵头制定多项国家标准,运营信创综合服务平台和适配验证实验室,已服务上万家科技企业。
◉ 国企换国产系统,到底难在哪?
软交所在服务大量国企客户的过程中,总结出三个最头疼的问题:
-
业务迁移难:原来用的 Windows 软件能不能跑?员工抱怨新系统不会用、效率低怎么办?
-
管不住:成百上千台电脑,怎么统一装软件、统一设权限、统一打补丁?外设(打印机、扫描仪)能不能用?
-
AI 怎么用:AI 聊天工具好玩,但怎么跟公司内部的知识库、业务系统打通?怎么真正帮员工干活,而不是添乱?

◉ 统信 UOS V20 先打了个好底子
-
软件兼容:统信 UOS 的应用商店和统信 Windows 兼容引擎,覆盖了绝大多数办公场景,基本不用担心“没法用”。
-
硬件兼容:主流国产芯片和超过 20 万款外设(打印机、高拍仪等)都能用。
-
上手容易:桌面设计贴近 Windows,员工基本不用重新学。还有一键迁移工具,把老电脑的文件、设置、应用一键搬过来。
-
企业管控:统信软件的“黄金组合”——桌面系统+集中域管平台+更新管理系统,能统一管理超过 40 万台终端,下发 150 多项精细化策略(比如禁止 U 盘、限制软件安装)。已在某大型国有银行落地,为 40 多万台电脑的国产化替换提供了保障。

◉ 统信 UOS V25 把 AI 真正变成了“干活的”
不只是聊天,而是能接入企业自己的知识库和业务系统。比如问“出差报销标准是什么?”系统从内部制度里找答案;说“帮我生成上季度销售数据分析报告”,AI 自动查数据、做图表、写报告。
统信桌面操作系统 V25 更进一步,把 AI 能力直接做到系统底层。只需说一句话,比如“把明天会议的材料准备好,发给参会人”,系统自己拆解任务、调取文件、发邮件。支持多智能体并行协作,效率极大提升。

04 联想开天

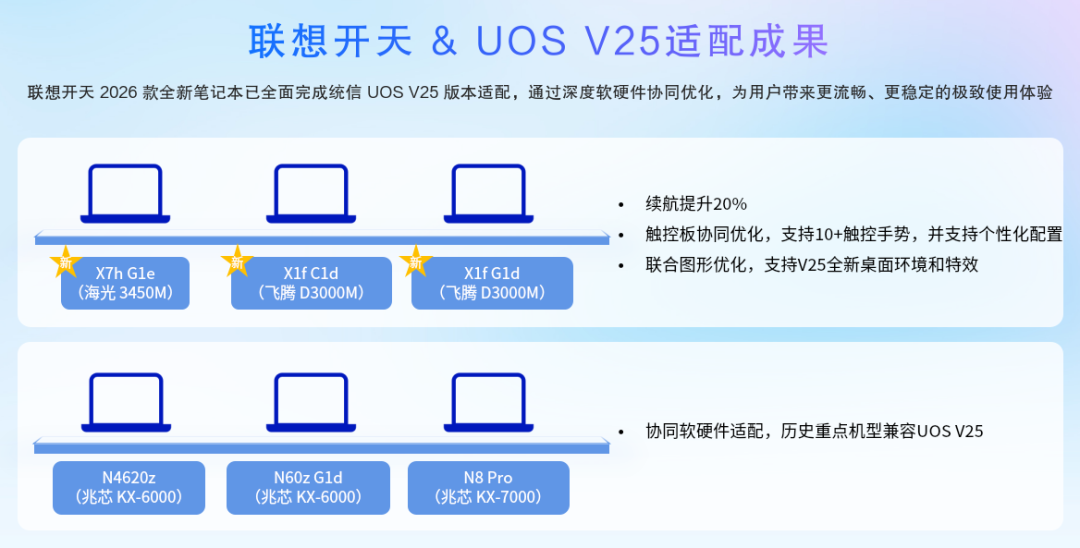
联想开天作为联想旗下信创品牌,专注于国产 CPU 平台的计算设备(涵盖笔记本、台式机、一体机),已连续 17 个季度位居信创市场出货量首位。针对统信桌面操作系统 V25 的发布,联想开天已率先完成全面适配,并致以热烈祝贺。
◉ 适配成果:主流配置全覆盖
-
笔记本:海光四号平台的 X7 系列、飞腾 D3000 的超轻薄机型、兆芯开先 6000/7000 系列,都已经和统信桌面操作系统 V25 深度适配。特别是触控板做了协同优化,支持几十种手势,续航也有提升。
-
台式机:海光三号/四号、兆芯开先 7000、飞腾 D3000、龙芯 3A6000 等平台,联想开天都有对应的台式机产品,全部完成适配。
◉ 联合推出“开天 Clou 信创 AI 一体机”
-
个人场景(适配小于 30 亿参数模型):面向单用户日常办公,支持文档处理、信息检索、数据图表生成等任务。
-
团队大脑:供小团队共享同一 AI 助手,协同完成方案撰写、会议纪要整理等协作工作。
-
企业级方案:面向全公司部署,可接入内部知识库与业务系统,实现规模化智能支撑。
安全层面,该一体机采用“机密 Token 技术”构建端到端的安全链路。此外,设备预置了多项精选技能(Skills),涵盖自动生成 PPT、Excel 数据分析、周报撰写等常用功能,实现开箱即用。
◉ 2026 年,联想开天要做两件大事
-
合纵连横:联合 CPU 厂商(龙芯、飞腾等)、操作系统(统信软件)、应用软件厂商、行业 ISV(独立软件开发商),一起打造信创生态底座,确保整个产业链自主可控。
-
尖刀突破:在教育、医疗、交通能源、运营商等行业,和行业 ISV 合作,做出差异化的解决方案。比如针对学校的电子教室、医院的病历系统等,做深度优化。
联想开天希望和统信软件一起,拿出跃马扬鞭的勇气,激发万马奔腾的活力,保持马不停蹄的干劲,把信创产业带向新高度。一起弄潮 AI,共赴山海!

从二十余年的技术深耕,到三大生产力的全面突破——统信桌面操作系统 V25 的发布,不仅是一个版本的迭代,更是国产操作系统从“追赶”到“并跑”的关键转折。
当 AI 成为新的生产力引擎,当安全与生态构筑起坚实的信任底座,统信 UOS 正在重新定义桌面的边界。它不再只是一个被动响应的工具,而是一个能够理解意图、拆解任务、协同执行的智能伙伴。
未来,统信软件将继续携手广大用户与生态伙伴,以智慧为魂、以高效为翼、以可靠为基,共同书写数字中国的新篇章。大成之作已来,未来更可期待。

编辑审校:公共事务部