
RAG 与向量数据库,从原理到落地
一、几百G资料如何转换成AI问答内容
有一个县城的全部县志。明清旧志、民国油印件、建国后的正式县志、二十年的年鉴、几百部族谱、政协文史资料、老照片……堆在图书馆的铁皮柜里,纸质的,落灰的。
有人说,现在AI这么厉害,能不能让AI读完这些东西,然后我问它”本县历史上最大的水灾是哪一年”,它就能告诉我?
能。但不是你想的那种”读完”。
二、AI 不是读完了所有书
这是最重要的认知纠偏。
ChatGPT、Claude 这些大语言模型(LLM),它们的”知识”来自训练阶段读过的互联网文本。但它们有一个硬限制——上下文窗口。
当前最强的 Claude,上下文窗口约 100 万 tokens,大约相当于几百页文档。而一个县的全部史料,纯文本可能有 100-500MB,相当于几万页。
差了 100 倍。装不下。
所以不能把几百G的扫描件全塞给AI,让它”读完”。这在物理上不可能。
三、不需要训练,需要检索
很多人的第一反应是”用这些县志训练一个AI”。
这是对”训练”的误解。训练一个大语言模型,是 Anthropic、OpenAI 这些公司花几千万美元、用几千张GPU、跑几个月才能做的事。其实不需要这样做,Claude 已经会理解中文了。
最重要的是让 Claude 在回答问题之前,先翻到正确的那一页。
这就是 RAG(Retrieval-Augmented Generation,检索增强生成)。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
| RAG | $0-100 | 建索引,问什么检索什么 | 这才是你需要的 |
打个比方:
我们去图书馆问”中国历史上最大的水灾?”
没有 RAG 的 AI:凭自己读书时的记忆回答。可能记错细节,甚至编一个听起来合理但不存在的事件——这就是 AI 幻觉(Hallucination)。
有 RAG 的 AI:先请图书管理员去书架找到最相关的 5 页,翻开摆在面前,然后基于这 5 页回答,并注明”见《卷二十·灾异》第 3 页”。
RAG 不是让 AI 更聪明,而是让 AI 有据可查。
四、完整管道:从纸到对话
一个县志智能问答系统的完整流程,分四个阶段:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
展开来看,核心步骤有五个:
步骤一:扫描
把纸质县志变成图片或 PDF。很多县图书馆已经做过数字化,直接拿扫描件就行。
步骤二:OCR(光学字符识别)
扫描件是图片,AI 读不了图片里的文字。需要 OCR 把图片变成可编辑的纯文本。
难度取决于原始材料的年代:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
现在开源的 PaddleOCR(百度)对中文识别非常好,古籍也有专门的模型。这一步成本接近零,耗时几小时。
步骤三:切片 + 向量化(核心步骤)
这一步是整个系统的心脏。分两件事:
切片(Chunking):把长文本切成小段落,每段 200-500 字。
比如《县志·卷二十·灾异》全文 20,000 字,切成 40 个片段:
-
片段 1:乾隆三年夏,淫雨四十日……(500字) -
片段 2:次年春,知县修堤……(500字) -
片段 3:光绪十九年秋,大水……(500字) -
……共 40 个片段
向量化(Embedding):把每个片段”翻译”成一串数字。
“乾隆三年夏,淫雨四十日,河溢,淹田三万亩”
↓ 经过 Embedding 模型
[0.12, -0.34, 0.78, 0.02, …] (1024 个浮点数)
这串数字编码了这段话的”语义指纹”。意思相近的文本,数字就相近。
这就是向量。Embedding 模型就是这个翻译机。
步骤四:存入向量数据库
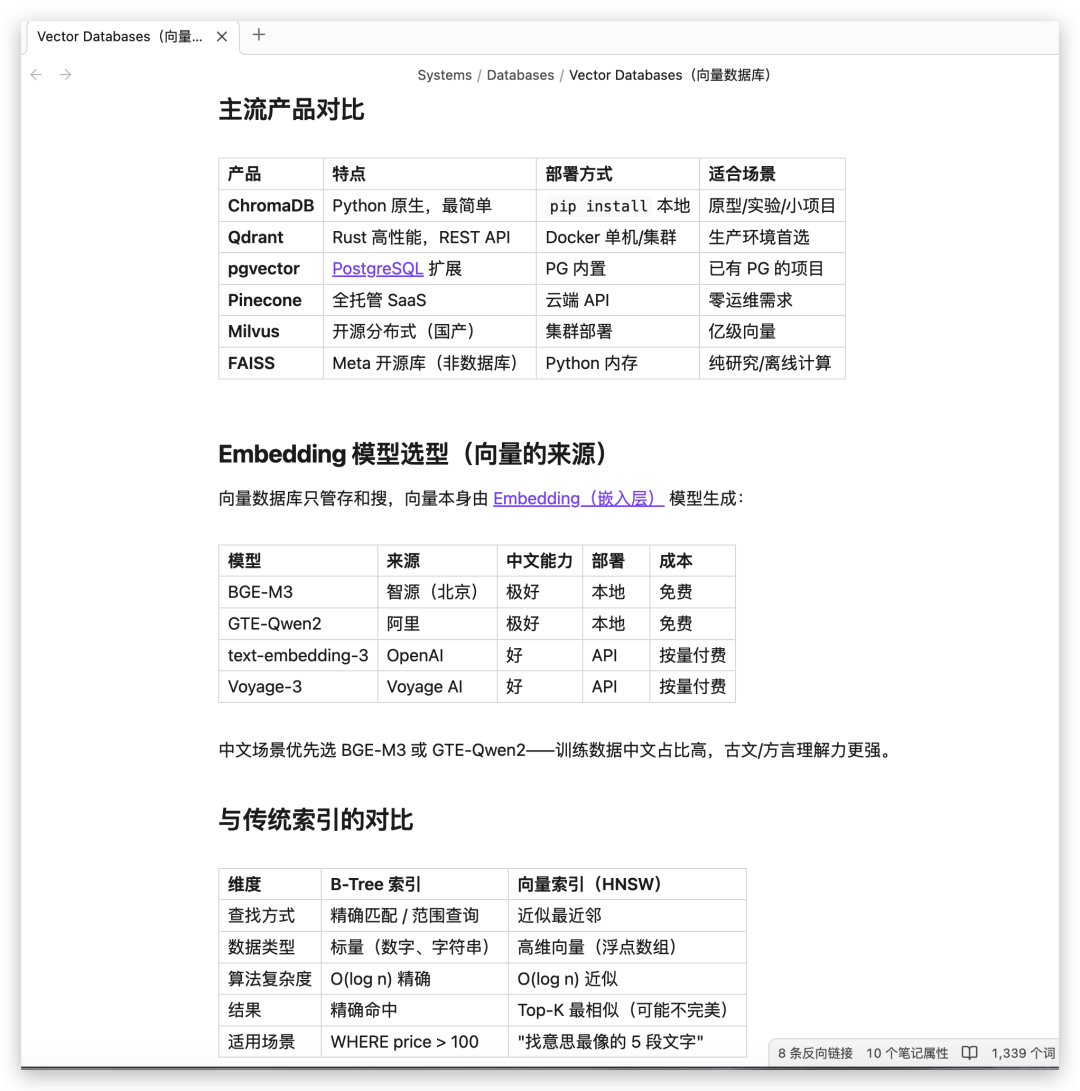
向量生成后,需要一个地方存储和检索。这就是向量数据库。
传统数据库(MySQL、PostgreSQL)的索引是 B-Tree,做的是精确匹配——”WHERE name = ‘张三'”。
向量数据库的索引是 HNSW 或 IVF,做的是近似最近邻搜索——”找出跟这段话意思最像的 5 条记录”。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
步骤五:检索 + LLM 问答
用户提问时,系统做三件事:
① 把问题也变成向量
“本县历史上最严重的水灾是哪一年?” → [0.11, -0.30, 0.80, …]
② 在向量数据库中搜索最相似的 5 个片段
命中:
– “乾隆三年夏,淫雨四十日,河溢,淹田三万亩…”
– “光绪十九年秋,大水漫城三尺…”
– “本县三面环水,历来多水患…”
③ 把这 5 段原文 + 问题一起发给 Claude
Claude 阅读后回答:
“据《卷二十·灾异》记载,本县历史上最严重的水灾为乾隆三年(1738年)夏季,连降暴雨四十日,河水漫溢,淹没农田三万亩……”
Claude 没有读完整部县志。它只读了图书管理员递过来的那 5 页。但这 5 页是对的。
不管是是Claude,还是ChatGPT,国产大模型Kimi、DeepSeek也可以轻松胜任,最后阶段仅仅是一个客服问答工作。
五、向量数据库的关系图谱
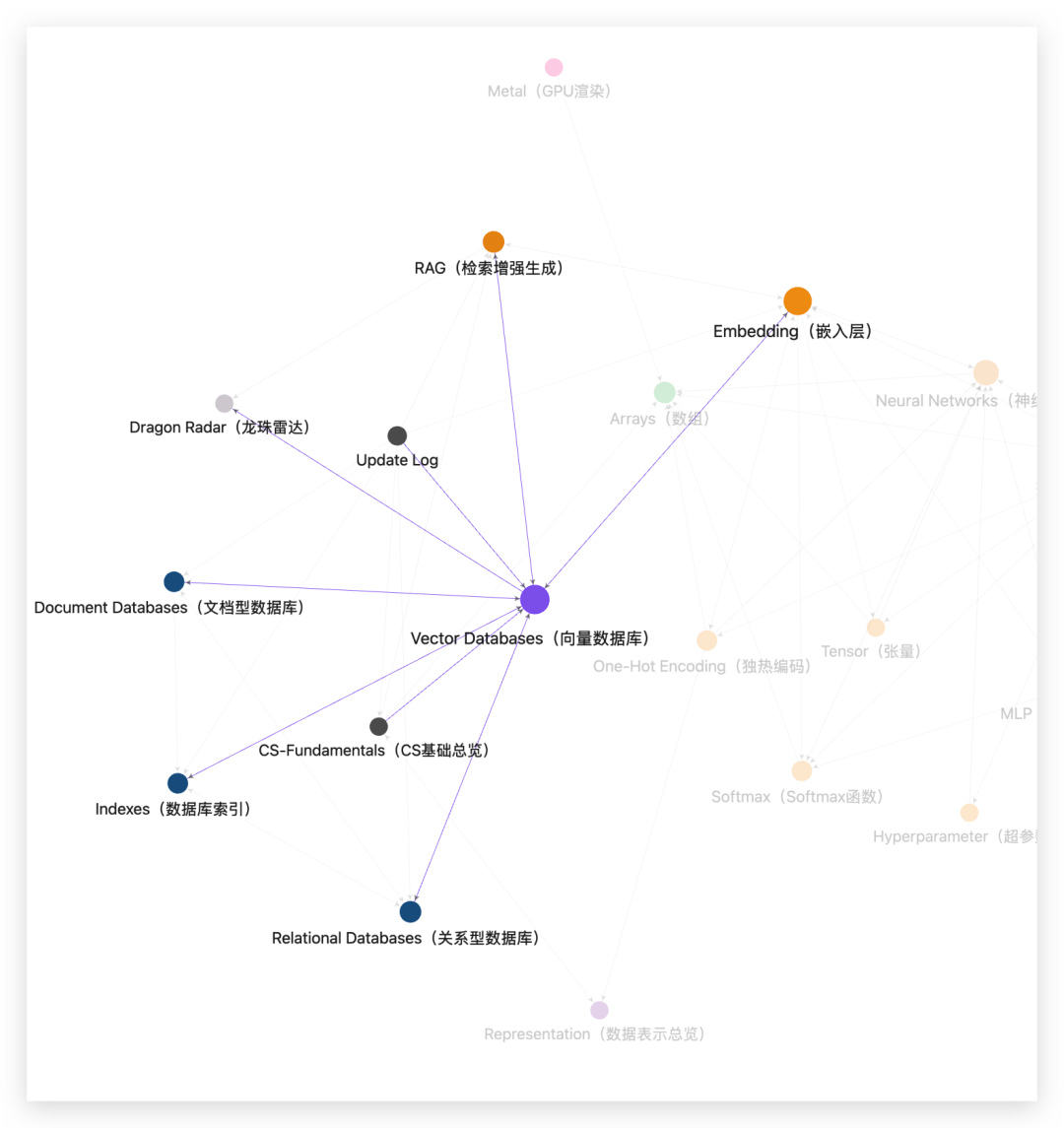
六、两个独立的选型决策
搭建 RAG 系统需要选两样东西,它们来自完全不同的厂商:
Embedding 模型(翻译机) — 负责把文字变成向量:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
向量数据库(仓库) — 负责存向量、搜向量:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
两者自由组合。BGE-M3 + ChromaDB 可以,GTE-Qwen2 + Qdrant 也可以。唯一的约束是向量维度要对齐——模型输出 1024 维,数据库就配置接收 1024 维。就像镜头卡口要匹配机身一样。
模型不存东西,数据库不懂语义。 模型负责”理解”,数据库负责”记住和找到”。
七、RAG过程中需要编程写代码吗?
需要。但不多。
不存在一个软件让你”选文件夹 → 点开始 → 等 → 完成”。需要写一个 Python 脚本,大约 50 行,串联整个流程。
核心代码骨架:
# 安装: pip install chromadb sentence-transformers
importos,chromadb
fromsentence_transformersimportSentenceTransformer
# 加载翻译机(首次运行自动下载模型,约 2GB)
model=SentenceTransformer("BAAI/bge-m3")
# 初始化仓库(本地文件,无需服务器)
db=chromadb.PersistentClient(path="./county-vectors")
collection=db.get_or_create_collection("县志")
# 遍历所有文本文件
forfilenameinos.listdir("./county-data"):
text=open(f"./county-data/{filename}").read()
# 切片:每 500 字一段
chunks=[text[i:i+500]foriinrange(0,len(text),450)]
# 翻译:文字 → 向量
vectors=model.encode(chunks)
# 入库:向量 + 原文一起存
forj,chunkinenumerate(chunks):
collection.add(
ids=[f"{filename}_{j}"],
documents=[chunk],
embeddings=[vectors[j].tolist()]
)
print(f"完成: {filename}, {len(chunks)} 个片段已入库")
这段代码做了三件事:加载模型、切片、存入数据库。在一台普通笔记本上,处理一整部县志(50万字)大约需要 5-10 秒。
八、需要 GPU 集群吗?
不需要。
这是很多人对 AI 项目的最大误解。整个 RAG 流程分三个层次,算力需求天壤之别:
整理几百G县志做的事属于 — 推理(Inference):
– 用别人训好的模型生成 embedding
– Mac 笔记本就够,零成本
– 100 万段文本,几小时跑完
大公司在做的事 — 训练(Training):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
本地做 RAG,全程都是推理,不是训练。
就像开车不需要造发动机。智源花了几千张 GPU 训好 BGE-M3 模型,我们 pip install 下载过来,直接用。
九、怎么知道结果准不准?
这是 RAG 系统真正的深水区。向量检索不是玄学,有系统性的评估方法。
第一层:人工抽检
准备 50 个我们自己写的问题(只有本地人才最懂县志),每个问题大家的记忆大概都知道答案出自哪里。跑检索,看返回的 5 段里有没有命中正确答案。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
第二层:对比实验
固定测试问题,换不同配置跑:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不需要理论推导,直接跑数据说话。
第三层:四个调优旋钮
如果准确率不够,依次尝试:
旋钮 1 · 切片策略(零成本,影响最大)
按自然段落切,不要硬切字数。保留章节标题作为前缀,如”【卷二十·灾异】乾隆三年夏…”。相邻片段重叠 10-20%,防止答案被切断。
旋钮 2 · 检索策略(零成本)
纯向量搜索能理解同义词,但可能漏精确词;纯关键词搜索精确匹配,但不理解语义。混合搜索——两者加权合并——是最佳实践。
旋钮 3 · 换 Embedding 模型(需重新跑一遍向量化)
BGE-M3 不够好就试 GTE-Qwen2,反之亦然。
旋钮 4 · 微调 Embedding 模型(成本最高,效果最好)
准备几百对训练数据,让模型学会”圩”和”堤坝”意思相近,向量应该靠近。
本质上跟所有工程一样:量化指标 → 对比实验 → 调参 → 再量化。不是玄学,其实还是应用工具链组合,进行工程管理。
十、部署上线的成本
以一个中等规模的县(10 万页扫描件)为例:
一次性成本:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
月度运营成本:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
| 月总成本 | ¥150-200 |
向量库是资产,大模型是水龙头。 水龙头可以随时换品牌(Claude、DeepSeek、豆包、通义千问),水库不能。谁先把一个县的数据向量化,谁就占了坑。
全国 2800+ 个县,99% 没有这样的系统。数据本身就是壁垒。
十一、总结
RAG 的本质: 不是让 AI 更聪明,而是给 AI 配了一个图书管理员。
向量数据库的本质: 不是存文字的数据库,而是存”意思”的数据库。
Embedding 模型的本质: 不是翻译语言,而是把语义翻译成数学。
整个系统的本质: 先建图书馆索引(一次性),再当智能图书管理员(持续服务)。
这个过程需要的不是训练AI。也不是需要采购GPU集群,更不需要几百万预算。
我们需要的仅仅是:一台笔记本,50 行 Python,磨合好的工具链,和一个值得被数字化的县城。